
Context, context, context…
If you’ve been around the evaluation block once or twice, you’ve no doubt heard evaluators talk about context.
“Context is SO important in evaluation.”
“Well, it all really depends on context.”
“You’ve just GOT to be aware of your local context.”
Sound familiar?
Evaluators will tell you time and again that context matters in evaluation: that there is no universal ‘right way’ to do an evaluation and that evaluation contexts—the settings in which programs, policies and evaluations are situated—necessarily affect the design, implementation and effectiveness of evaluation practice.
All this talk about context has even made its way into evaluation-related policy and practice documents. The American Evaluation Association’s (AEA) list of evaluator competencies, for example, dedicates an entire domain (the Context domain) to understanding context. So does the Australian Evaluation Society, whose list of competencies charges evaluators with the responsibility to be “cognizant of, and responsive to” their contexts.
But what, exactly, do people mean when they talk about context? And what, specifically, should an evaluator look for if they want to respond to the uniqueness of their context?
Hoping to gain some clarity on these very questions, last year I took to the (metaphorical) streets to find out. Over a 12 month period, I interviewed 12 AEA award winners and surveyed more than 400 evaluators from Australia, New Zealand and the United States, hoping to pull together an an actionable list of features that collectively make up one’s context.
The product?
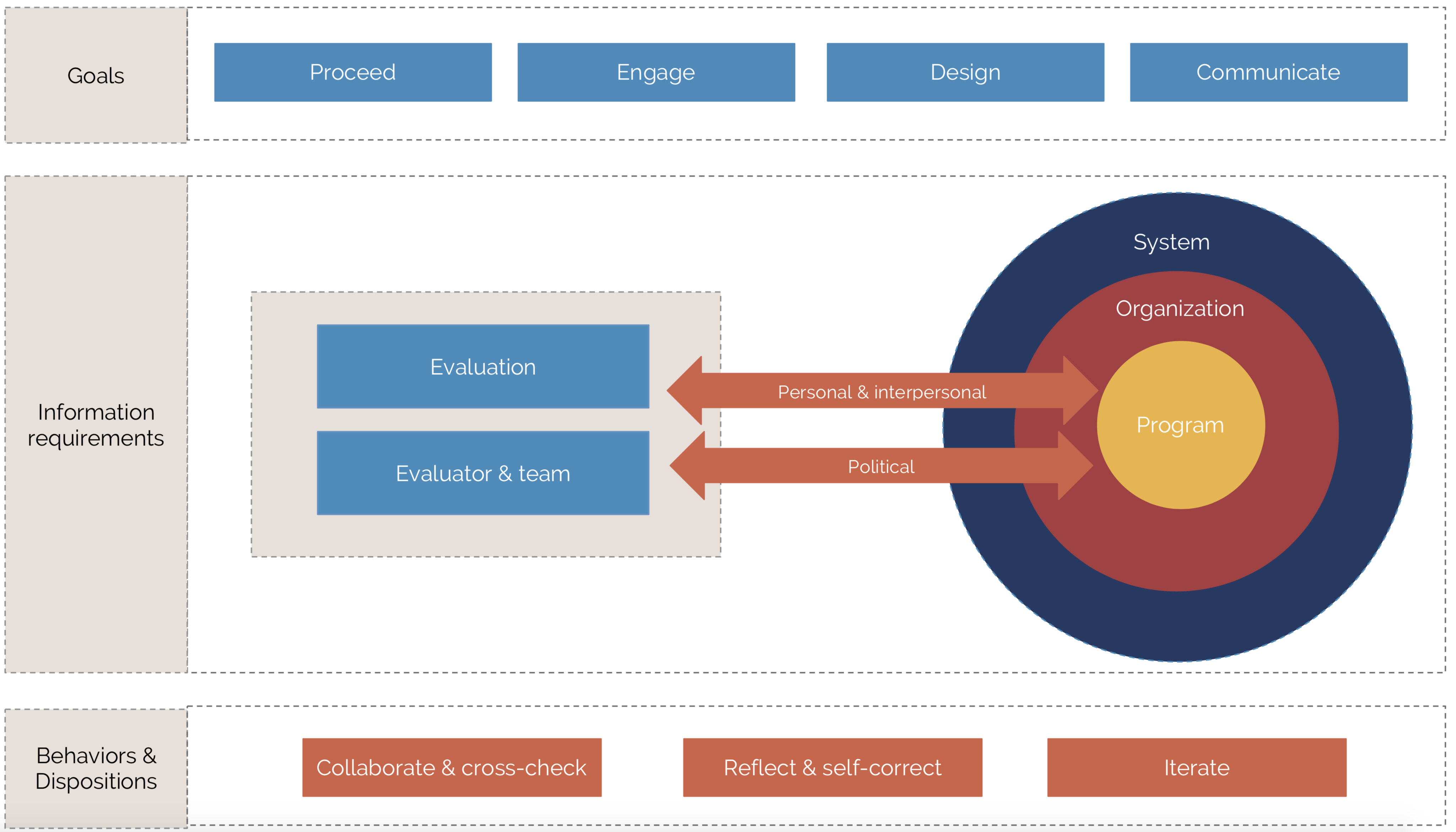
The Framework for Situation Awareness in Program Evaluation: a list of 70 “information requirements” that define what evaluators could (and should) pay attention to if they want to understand—and respond to—their contexts.
In short: evaluators around the world say we should look for information about seven key features of context:
- The program we’re evaluating (e.g. What do they do? How controversial are their activities?)
- The organization delivering the program (e.g. Who is in charge? Who makes the decisions?)
- The broader systems and structures within which the program and organization operate (e.g. What changes are underway in the broader system? Who else does the program depend on to get things done?)
- The evaluation itself (e.g. What decisions will it inform? How much is at stake?)
Additionally. we need to pay attention to ourselves, the evaluation team (e.g. Where do we sit in relation to our context? What are our biases? How well do our capabilities fit the needs of this specific evaluation?)
Finally, cutting across all these categories, we need to pay attention to:
- The personal and interpersonal relationships embedded in our evaluation (e.g. Is there anyone with a big or volatile personality? How much do these people care about this evaluation?), and last but certainly not least:
- The political elements of our evaluation: Who stands to win (or lose) from positive (or negative) findings?
Across the globe, evaluators use these pieces of information to figure out what to do in their evaluation contexts. Specifically, they use these pieces of information to (1) decide whether they should do the evaluation at all, (2) figure out how to build and maintain engagement in the evaluation process, (3) design an evaluation that will work in the given situation, and finally, (4) communicate evaluation findings with influence.
What next?
We’re Beta testing the Framework for Situation Awareness in Program Evaluation as a practical tool for evaluation practitioners.
We think evaluators might be able to use the Framework to more intentionally embed context into evaluation planning and practice. For example, evaluators might use it:
- As a planning document—to help orient your thoughts about your context at the beginning of an evaluation process
- As a self-assessment tool—to help you figure out what you know (and what you still need to find out) about an evaluation situation
- In a myriad of creative ways that we haven’t yet thought of…
If you’d like to try it out, download the framework, then let us know how you used it and how it went. What worked? What didn’t? What should we change to make a more helpful tool for evaluators like you?


